I've got some work to do! I do know that when I looked at ThruLines, I added all those descendant matches to a "Steinbrecher" group I created. Then looked at each of them individually and see if they matched each other. I went through the first 3 matches and they match 10,12 14 people in that Steinbrecher group that I had created and added those descendants to. So that's a positive sign perhaps?
The level of work varies depending on the quantity and quality of your matches. If you have a very thick cluster of matches, say with 1st, 2nd, 3rd, 4th, 5th, 6th cousins within it, by going through all the obvious clustered matches you should be able to find a lot of matches with common or potentially common ancestry (less time). Other times the clusters of matches can be a bit more fragmentary. You can have 2-3 clusters of DNA matches that don't overlap, despite sharing the same ancestors. For other lines of ancestry there may be very few discernable descendants with DNA tests - if any.
It's hard to tell based on comments on a forum regrading this:
the first 3 matches and they match 10,12 14 people in that Steinbrecher group, but it sounds like this is a cluster.
If you put them all in a graph showing which are shared matches and it looks something like this:
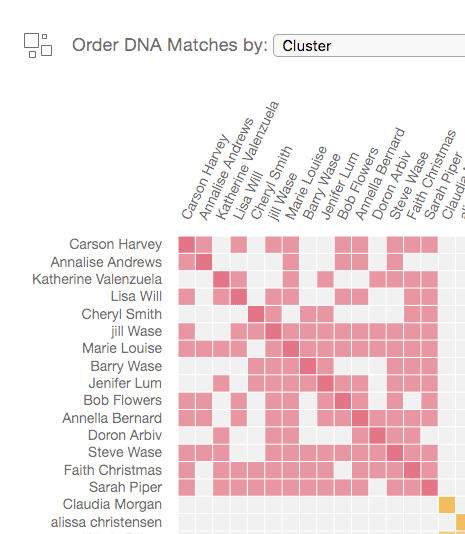
Then that is a cluster, and you'd expect to find common ancestors among the matches. You can have shared matches on the same line that happen to cluster with none of the other matches, or as mentioned, more than one cluster for the same line of ancestry. There's a range of things you can expect.
You can appraise matches, even with basic trees quite quickly, by opening up the dead-ends in the tree, then press 'Search' at the top and you will typically find other trees with a continuation of the line:

Those trees can, of course, have errors, but this saves you having to research 100s and 1,000s of other people's trees.
ProTools is very useful for figuring out some unknown clusters, as it better pinpoints the relevant lines of ancestry. It also helps save time by letting you single out the most obviously related matches.
